Tern
I spend a rather large fraction of my days inside Emacs, writing and editing JavaScript code. Of this time, a significant amount is spent doing things that follow patterns. Pattern which, with a little machine intelligence, could easily be automated.
Years ago, before accidentally rolling into this JavaScript career, I mostly programmed Common Lisp. Emacs integration for Common Lisp is divine. It does just about everything, from interactively exploring and modifying a running system, to debugging, to looking up documentation for you on the web. But the main two things that made day-to-day programming in that environment so wonderful were that it automatically showed me a list of argument names when I was typing arguments to a function call, and that it allowed me to jump to the definition of something at a single keystroke (and then jump back to where I came from at another keystroke). This meant that I hardly ever had to break my flow to go look up the interface for a function, or wonder how or where something is implemented.
One thing about machine intelligence is that machines don't develop it spontaneously. Someone has to put in the time to teach them. Since programming-language geekery is my thing, and having even half-decent JavaScript integration for my editor would save me a lot of time, I've started exploring this problem.
Early this year I got a prototype off the ground that did a passable job at the basic features that I wanted (argument hints, jump-to-definition, and of course decent auto-completion). Using that prototype, I duped the crowd into kindly spotting me some money to continue working on it. The result is called Tern (github), which is now an editor-independent static analysis engine that is being integrated into several different editors.
In this post, I'll try to document how Tern works.
General approach
As a first step, Tern parses your code using Acorn. If it's not currently syntactically valid because you are in the middle of editing it, it still parses it, using the error-tolerant parser in Acorn.
It then, in a first pass, builds up a representation of the scopes in
the program. If we ignore with and some of the nasty behavior of
eval (which Tern does), scopes in JavaScript are entirely static and
trivial to determine. This already gives us enough information to
auto-complete variable names, and jump to the definition of variables.
But we also want to complete property names, show argument hints, and jump to the definition of functions and types that are, for example, stored in a property.
For this, we need to figure out the types of the program's elements. This is the central problem that Tern tries to solve. In a language like JavaScript, it is a rather challenging problem.
Type inference algorithm
The type inference in Tern is done by a second pass (after the one that builds up the scopes) over the code. You can picture this pass as building up a graph that represents the way types flow through the program.
Each variable and object property, as well as some kinds of
expressions, will have an abstract value associated with them. This is
a set of types that have been observed for this element. These are the
nodes in the graph. The edges consist of forwarding information. For
example, if the expression y = x is found in the problem, the
abstract value for variable x will be set to propagate all types it
receives to the abstract value of y. Thus, if x is somehow known
to be a string, y will also get type string (but might, depending on
how it is used, receive more types than just that).
The graph may be initialized from one or more definition files,
which are a simple JSON data format that contain information about
global variables and their types. Such files for the basic JavaScript
environment and the interface exposed by browsers are included in the
Tern distribution. These tell Tern that, for example, the parseFloat
global holds a function type of one string argument that returns a
number.
Let's see what the graph would look like for this pointless program.
var x = Math.E;
var y = x;
var z;
x = "hello";
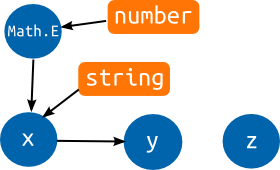
You see blue circles that represent the abstract values for our three
variables and for the Math.E property. The orange boxes are actual
types. The basic ECMAScript definition file has given Math.E the
type number. Since it is then assigned to x, an edge is added from
Math.E to x, which causes x to also get the number type. y is
initialized to x so it gets all of x's types. When x is assigned
a string value, the string type flows into it and, consequently, also
into y. The variables now have both the string and number type
associated with them.
Variable z is never written to or read, so it just sits there sadly
in its corner, without any connection to the rest of the program, and
its abstract value remains empty.
Note that in actually executing this program, x would end up with a
string and y would still be simply a number. Tern ignores control
flow and pretends everything in the program happens, basically, at the
same point in time. This is an approximation that's not correct, but
that makes the graphs a lot easier and cheaper to construct. For
typical programs, it doesn't have much of an adverse effect on the
quality of the inference.
Propagation of types is not always direct. In many cases, the algorithm will assign a specific propagation strategy, which may contain arbitrary code, to handle types that appear in a source abstract value.
The most common case of this is function calls. For every function call in the program, a propagation strategy object is created that knows the arguments that were passed to the function, and has an abstract value that represents the result type of the call. The type of the callee is set to propagate to this object. When it receives a function type, it will set the argument types of the call to propagate to the argument variables of the function type, and set the return type of the function type to propagate to the call's result type.
This means that function types must hold references to the abstract
values for their argument variables, and for an abstract value that
represents their return type. (And, in fact, another one that
represents their this type, though we'll ignore that in the next
example.)
function foo(x, y) { return (x + y); }
function bar(a, b) { return foo(b, a); }
var quux = bar("goodbye", "hello");
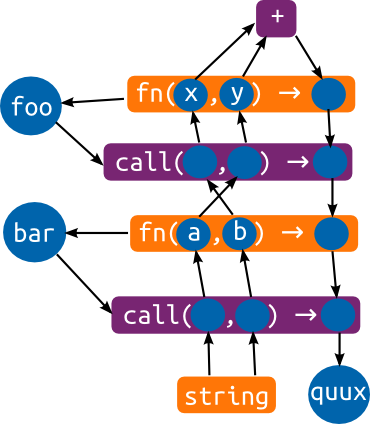
You can see the function types, as orange boxes, containing
(references to) abstract values. Function declarations will cause such
types to be created, and added to the variable that names the
function. The purple boxes are propagation strategies. There are two
calls in the program, corresponding to the two purple call boxes. At
the top is a simple box that handles the + operator. If a string is
propagated to it, it'll output a string type, and if two number types
are received, it'll output a number type.
The arrows going into the arguments and coming out of the result type of the call propagators are added as soon as the call is seen. The arrows coming out of the arguments and going into the results are added when an actual function type is found for the callee.
You can follow the string types that are passed to bar through this
graph, being joined together by the + operator into a single string,
and then flowing back down through the return types and into the
quux variable.
In this program, every value was used in a single way, causing almost all the elements to neatly have a single ingoing and a single outgoing edge. This is not typical for real code. Every assignment to a variable will add another incoming edge, and every time it is read, another outgoing edge is added. In a big program, variables that are referred to a lot will have hundreds of outgoing edges. It very quickly becomes impossible to visualize the type graphs for real programs in two dimensions. (I already had to go through three throw-away sketches before I found a layout for the above graph that was not a tangled mess of crossing arrows.)
Tern defines a number of other propagation strategies, handling things like property reads and writes, and creating instances from constructors. These work in ways analogous to the call strategy described above.
An important feature of these type graphs is that no matter in which order they are built, the final result will be the same. If you call a function that is only defined later in the program (or in a file that is defined later on), your call node will sit there patiently waiting until a type is propagated to it. And when that finally happens, it'll set up the necessary edges in exactly the same way that it would have done if the function had been seen before the call.
Source-less sub-graphs
One important property of this inference algorithm is that it will only give types to things when the types are actually observed being assigned or passed to it. This is fine, most of the time, but can be a problem for functions that are never called—no types will flow into the function's arguments.
Why would you write a function and never call it? Usually because you are writing a library.
Tern doesn't fundamentally solve this problem, but it uses a trick to
be able to show at least something, even for abstract values that
don't have any definite value. By looking at the propagations made
from an abstract value, it is often possible to get some clue on the
way it is used. If, for example, it is propagated to a variable that
usually holds numbers, it might just be a number. If its charCodeAt
property was accessed and the only type we know of with a charCodeAt
property is the built-in string type, it's probably supposed to be a
string.
Guessed types are not added to the actual type graph. They are only returned when directly asking for the type of an abstract value that has no known type. This means that if you have a function like this...
function gurble(frobs) {
return frobs.reduceRight(function() { /* ... */ }, 0);
}
... Tern will consider the frobs argument to be an array when
displaying argument hints, but won't actually propagate anything to
the return type, because it isn't sure (and once a type is propagated
into the graph, there's no way to un-propagate it).
Run-time type construction
Here's a pattern that's relatively common in JavaScript code:
function extend(proto, props) {
function Ctor() {}
Ctor.prototype = proto;
var obj = new Ctor();
if (props) for (var prop in props) obj[prop] = props[prop];
return obj;
}
This creates a new object that extends another object with some new properties.
The type of the resulting object is not 'visible' in the source code. It is dynamically created at run-time. Yet, if a piece of code uses this pattern to set up its types, Tern will completely fail to understand it unless it can properly interpret what the code is doing.
And now we're off into dodgy hack land. In order to meet this
challenge, Tern uses a special treatment for for/in loops that
appear to be copying properties. When it encounters them, it assumes
that the properties from the source object will be copied to the
target object. It ignores control flow (conditionals and such) and
simply copies all properties.
That solves half the problem. Now if you call extend once, it will
create a new object type at the new expression, copy in the
properties from props, and return it, resulting in more or less the
type you'd expect.
But, if you create multiple types using extend, you'll run into
another problem. All of them will have the return type of extend
flow into them, and the return type of extend will be all of them (a
function has a single abstract value representing its return type).
Thus, you'll end up with a useless mess that will have little to do
with your intended object types.
To fix that, Tern uses a heuristic to determine whether a function is a type manipulating function, and if it decides that it is, its return type will be computed in a different way. Instead of building a type graph for the function's content once, and connecting that to all argument and return types, the function is 'reinterpreted' for every call site, creating propagations only for the current arguments and return type.
(Conceptually, all functions that aren't recursive could be interpreted this way. It would probably produce superior results, but also be much, much more expensive.)
The heuristic to determine whether a function manipulates types or not
is rather superficial, and will only catch the pattern in the example
above and a few similar things. Every time a function assigns to a
prototype property, instantiates a locally defined constructor, or
copies properties in a for/in loop, a score is incremented. When
this score, divided by the size of the function, crosses some
arbitrary threshold, the function is marked as a type manipulator.
Generic functions
The previous section already mentions how Tern's model of representing the return type of a function with a single abstract value can lead to bad results. A similar issue is seen with functions like this:
function randomElement(arr) {
return arr[Math.floor(Math.random() * arr.length)];
}
If you first pass it an array of numbers, and then an array of booleans, the number and boolean types will both be flowing into the result of any call site of the function.
To gracefully deal with functions like this, Tern tries to determine,
after it analyzed a function, whether it is a generic function that
has a return type that directly depends on its input type. To do this,
it again makes use of the type graph, by performing a graph search
trying to find a path from one of the arguments to the return type. It
doesn't search very deep, since that'd quickly get expensive, but for
example the randomElement function above has a simple path from
arr, through a propagation object that propagates the element type
of the array, to the return type.
For calls to randomElement, instead of propagating from the
function's return type abstract value, we simply take the element type
of the type (or types) of the first argument, and use that. This'll
correctly type randomElement([true]) as a boolean, and
randomElement([1]) as a number.
The server
The inference engine makes up most of complexity of the project. But above it is another layer, the layer that most client code talks to, which is not entirely trivial. In order to support an editor, we must also be able to maintain an up-to-date view on a code base as it is being edited.
This is where the server component comes in. It keeps track of a set of files, analyzes them, and answers queries about the code. Here's an example of a request to a Tern server (requests are JSON documents):
{
"query": {
"type": "completions",
"file": "myfile.js",
"end": 20
},
"files": [
{
"type": "full",
"name": "myfile.js",
"text": "var foo = document.f"
}
]
}
It uploads a small file to the server, and asks for completions at character position 20. The server might respond with:
{
"completions": ["firstChild", "forms"],
"start": 19,
"end": 20
}
Your editor could then use this information to provide actual auto-completion.
The query/files format for request is intended to make it easy for
editor plugins to update the server's view of the code as they are
making requests. The server will save the files, so that if multiple
requests are made without the document changing, there's no need to
re-upload the code again and again.
There is also support for sending only a fragment of a file, providing some context for the request but requiring this fragment to be analyzed in the context of a previously built up type graph and scope tree for the whole file. This is useful when dealing with big files—analyzing 6000 lines of code can take up to 300 milliseconds, which is too much for an interactive interface. If the 6000 lines were analyzed in advance, in the background, and when auto-completion is triggered, only the 100 or so lines around the cursor are sent to be re-parsed and re-analyzed, the server can usually respond in under 30 milliseconds.
Another responsibility of the server is managing plugins that
influence the way files are loaded. There are currently plugins for
RequireJS and node.ns, which will automatically try
to load dependencies, so that modules loaded through define or
require will have their types understood by Tern.
Related work
In closing, I want to give a quick overview of related work. This list is incomplete. There are tools (such as VJET for Eclipse) on which I couldn't find any detailed technical information, and there are likely others that I am not even aware of. You are encouraged to write me if you have corrections or additions.
Microsoft Visual Studio
Since VS 11, 'Intellisense' for JavaScript is nothing short of amazing. It works, as far as I understand it, by actually running your code in a magic invisible way, instrumenting the Chakra engine to ignore I/O and cut off loops that run too long or recursion that goes too deep, and then inspecting the resulting JavaScript environment to find out what actual types were created for a given variable or expression. This makes it amazingly accurate, even when you're doing very odd things with your types. Downside is that it'll sometimes not be able to run the code that you need a completion for with its actual input types (it needs to find a code path leading to that code, which can be tricky), and thus fail to provide completions.
If you're curious about this technique, there's a very watchable video of a presentation by Jonathan Carter on this subject.
Scripted's Esprima-based content assist
The Scriped editor is a relatively new code editor with a focus on editing JavaScript. It comes bundled with a plugin that parses your code and runs a type inference algorithm on it in order to provide completions. This is similar to the approach taken by Tern, except that its inference algorithm is very different. From a quick reading of the code, it appears to be mostly bottom-up, with a second pass that does some propagation. See also this blog post.
jsctags and doctorjs
jsctags is a tool that generates Ctags files
from JavaScript code. doctorjs is a fork of jsctags which
uses a more advanced form of abstract interpretation in its inference
algorithm.
Both projects have been more or less abandoned, and don't yield very
good results. They did influence (mostly through Patrick Walton's
doctorjsmm experiment) the design of Tern a lot. But I've
always felt that the static, non-interactive way Ctags (or Etags)
work, which undoubtedly made sense back when they were invented, is
awkward and not really appropriate anymore. Tern uses a 'live' data
source—a process that updates it analysis as you change the
code—instead.
SpiderMonkey's type inference
The inference algorithm that doctorjsmm tries to implement is based
on the type inference subsystem of the SpiderMonkey JavaScript
engine. Tern's algorithm is also closely based on this technique
(outlined in this paper).
However, a JavaScript compiler and an editing assistance plugin have quite different goals, and thus also quite different requirements for their type inference algorithms. SpiderMonkey's compilation process has to be lightning fast, and Tern can take (a little) more time if that happens to improve results. SpiderMonkey has to be conservative, since producing incorrect information to the compiler might result in segmentation faults or exploitable bugs in the compiled code. Tern can more freely use approximations, since getting an inaccurate auto-completion doesn't usually cause disaster. And finally, SpiderMonkey's type inference can use feedback from the actual running code. Tern doesn't run the code, so it doesn't have that luxury.